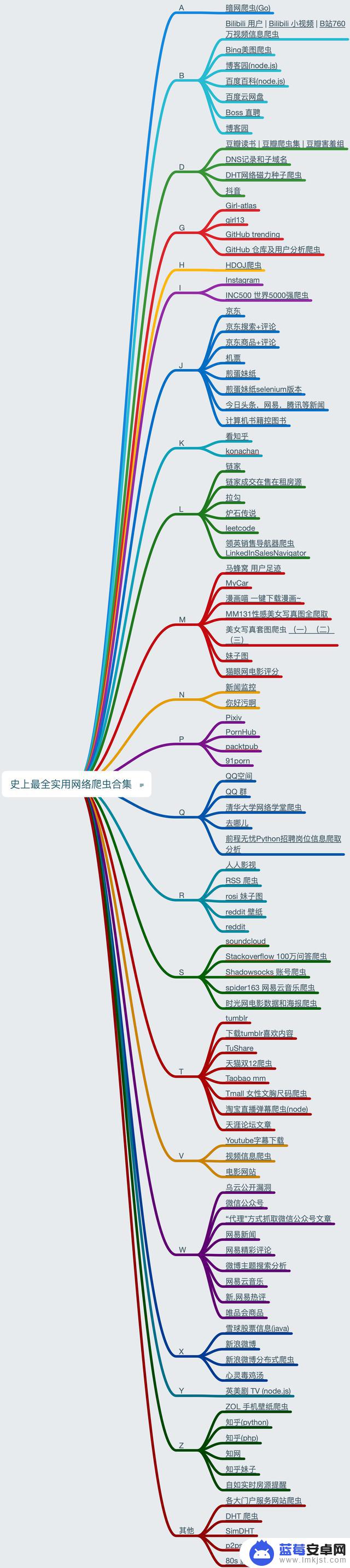
*不带括弧注明的默认都是 Python爬虫
A
暗网爬虫(Go)B
Bilibili 用户 | Bilibili 小视频 | B站760万视频信息爬虫Bing美图爬虫博客园(node.js)百度百科(node.js)百度云网盘Boss 直聘博客园D
豆瓣读书 | 豆瓣爬虫集 | 豆瓣害羞组DNS记录和子域名DHT网络磁力种子爬虫抖音G
Girl-atlasgirl13GitHub trendingGitHub 仓库及用户分析爬虫H
HDOJ爬虫I
InstagramINC500 世界5000强爬虫J
京东京东搜索+评论京东商品+评论机票煎蛋妹纸煎蛋妹纸selenium版本今日头条,网易。腾讯等新闻计算机书籍控图书K
看知乎konachanL
链家链家成交在售在租房源拉勾炉石传说leetcode领英销售导航器爬虫 LinkedInSalesNavigatorM
马蜂窝 用户足迹MyCar漫画喵 一键下载漫画~MM131性感美女写真图全爬取美女写真套图爬虫 (一)(二)(三)妹子图猫眼网电影评分N
新闻监控你好污啊P
PixivPornHubpacktpub91pornQ
QQ空间QQ 群清华大学网络学堂爬虫去哪儿前程无忧Python招聘岗位信息爬取分析R
人人影视RSS 爬虫rosi 妹子图reddit 壁纸redditS
soundcloudStackoverflow 100万问答爬虫Shadowsocks 账号爬虫spider163 网易云音乐爬虫时光网电影数据和海报爬虫T
tumblr下载tumblr喜欢内容TuShare天猫双12爬虫Taobao mmTmall 女性文胸尺码爬虫淘宝直播弹幕爬虫(node)天涯论坛文章V
Youtube字幕下载视频信息爬虫电影网站W
乌云公开漏洞微信公众号“代理”方式抓取微信公众号文章网易新闻网易精彩评论微博主题搜索分析网易云音乐新.网易热评唯品会商品X
雪球股票信息(java)新浪微博新浪微博分布式爬虫心灵毒鸡汤Y
英美剧 TV (node.js)Z
ZOL 手机壁纸爬虫知乎(python)知乎(php)知网知乎妹子自如实时房源提醒其他
各大门户服务网站爬虫DHT 爬虫SimDHTp2pspider80s 影视资源爬虫 - JianSo_Movie什么是爬虫爬虫是一种可以爬取指定网站页面的指定信息的应用程序,通过爬虫。我们可以获取网站中我们需要的数据。
爬虫的核心逻辑包括以下几个步骤:
通过一个 URI 地址,模拟类似浏览器的行为获取这个 URI 地址对应的 HTML 页面,部分爬虫甚至还可以支持 JavaScript 的执行。获取之后通过页面解析,从页面中的指定的 HTML 标签下提取得到我们需要的数据。对数据进行处理之后存入指定的存储,比如文件系统,MySQL 等关系型数据库,Redis,MongoDB 等 NoSQL 数据库中。继续爬取其他的 URI 地址,这些 URI 地址可以从之前爬取得到的页面中提取,也可以通过一个 URI 库直接由启动爬虫的用户来输入。继续回到步骤1爬取并分析页面。爬虫技术目前经常遇到的难点问题:
登录及验证码:有些页面在爬取的过程中,经常会遇到页面的交互操作。比如需要你输入用户名及密码进行登录才可以获取,有的网站还会提供验证码进行验证,这一类的数据获取都非常不容易。
JavaScript 等异步数据:部分网页的数据并不是在网页加载后就能够获得的,需要执行 JavaScript 来获取然后再更新到网页,这种情况下部分爬虫是无法爬取到的。通常会采用的解决方案是模拟浏览器去访问页面并执行 JavaScript 后获得完整的数据再进行页面解析。
反爬措施:有些网站会禁止无限制的爬取,会对 IP 地址及 User Agent 等爬虫标志进行限制,避免网站因为爬虫造成压力过大或者信息泄漏。在这种情况下,很多爬虫会选择进行 User Agent 伪装或者 IP 代理池的机制。
什么是通用爬虫?这里所说的通用爬虫指的是能够爬取任何网站页面的爬虫,常见的爬虫都是特定的爬虫,特定爬虫需要根据爬取的目标网站进行设计实现。比如知乎爬虫或者豆瓣爬虫,这一类的文章在网上可以找到很多,都会针对于知乎及豆瓣的特定页面进行分析,并设计爬虫的实现逻辑。

以上就是抖音数据爬虫选题的详细内容,更多抖音爬虫数据采集内容请关注蓝莓安卓网其它相关文章!












