语音识别的主流语言中文、英文等开源语料库都很丰富,比如说:THCHS-30、Aishell、LibriSpeech等。但是很多的国家地区的开源语料库却很少,比如:巴基斯坦、巴西、重庆话等。首先对产生这种问题的原因进行简单的分析:语料库需要很大的人力成本需要专人去录制和标注,一般大点的语料库都是上千小时非常费时费力。那作为一个底层的研究人员咱没钱又想整个稍微靠谱点的地方方言语料库咋整呢?
方法&思路我就简单的构思了一下,这不短视频时代的到来了吗?Tiktok、抖音、B站等一系列短视频平台都有各种地方人群发布地方方言视频并且配字幕的。我就琢磨啊,一个视频里面字幕也有音频也有我是不是可以从里面把这个东西弄出来?下面是我不成熟的思路:
1. 我的目标:获取字幕和对应音频
2. 判断音频开始和结束,一般一个视频的音频和字幕为了让观众看的顺畅,在时间上都是有对应关系。我只需要判断相同字幕开始视频帧和结束视频帧就ok了。
3. 字幕识别这个就是一个OCR(Optical Character Recognition,光学字符识别)。简单来说就是在视频帧上面找字然后转录成文字。
4. 最后把得到的字幕保存在抄本(Transcript.txt)文件里面,其他的以.wav形式保存
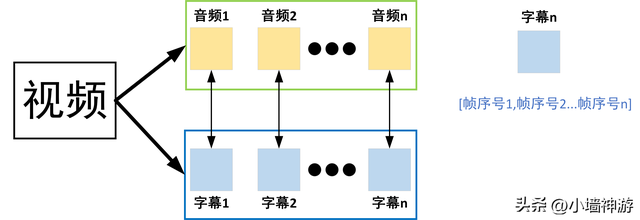
上面这个图就是大概的思路图。
实现代码头文件导入:给大家解释一下我用的这个ocr是啥,这个是来自github上的一个开源OCR代码,这里是链接。环境要是不会搭建的话,下期再出个环境搭建。
总结我这个不成熟的想法其实还有很多吐槽的地方,比如:视频获取得到应该一样的字幕的那段时间,可能他们每一帧字幕不一样。产生的原因:可能是ocr识别准确度不太行(识别错)、视频本身的视频帧有问题。以后估计还会改进吧。
运行效果图
以上就是抖音录像怎样出字的全部内容,希望可以帮助到大家!












